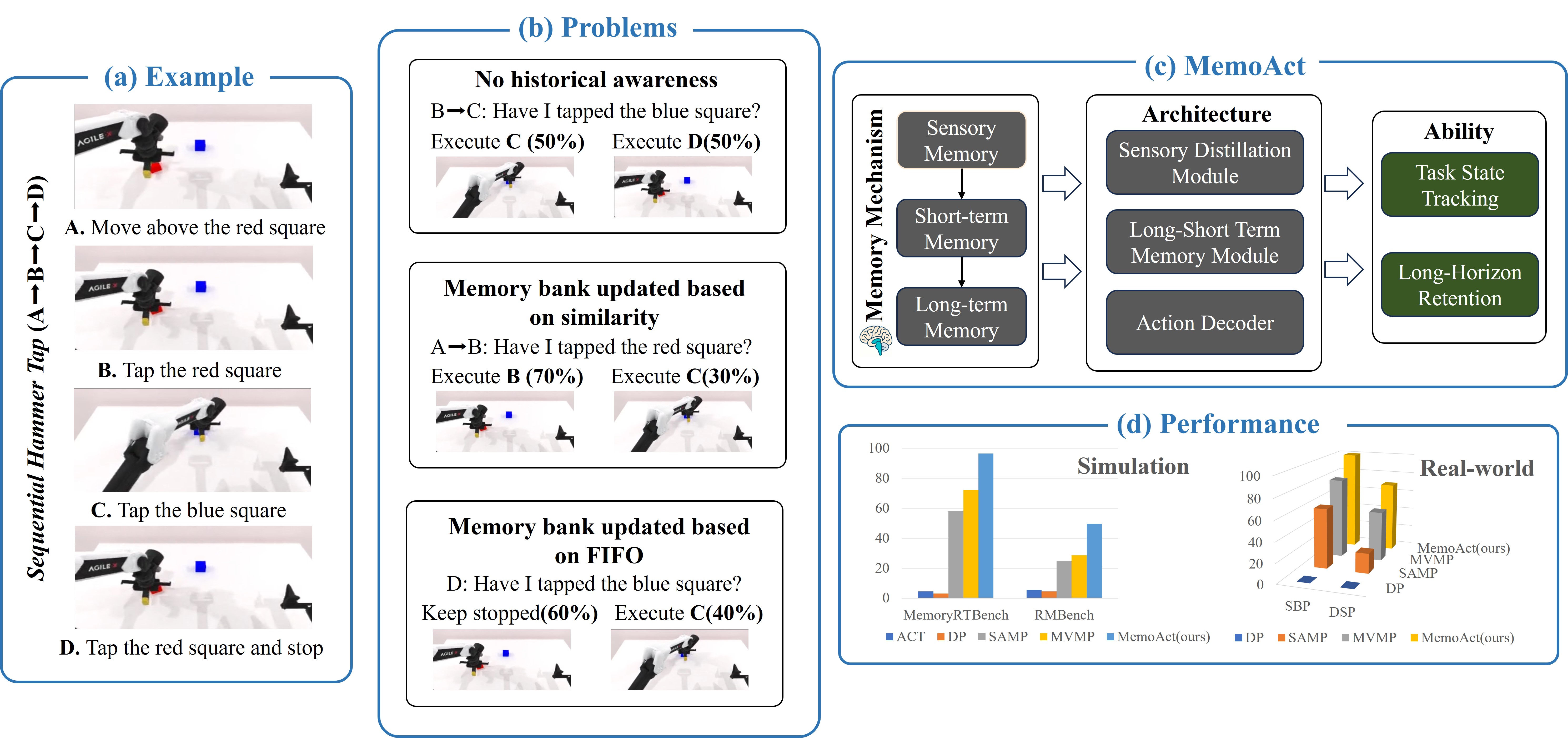
(a) An example of a memory-dependent task. (b) Policies lacking historical awareness fail under identical observations, while existing representative memory mechanisms suffer from limited long-horizon retention and poor task-state tracking. (c) Inspired by the Atkinson–Shiffrin memory model, we propose MemoAct, which simultaneously enables precise task-state tracking and robust long-horizon retention. (d) Results on MemoryRTBench, RMBench, and real-world experiments demonstrate that MemoAct significantly outperforms baseline algorithms.
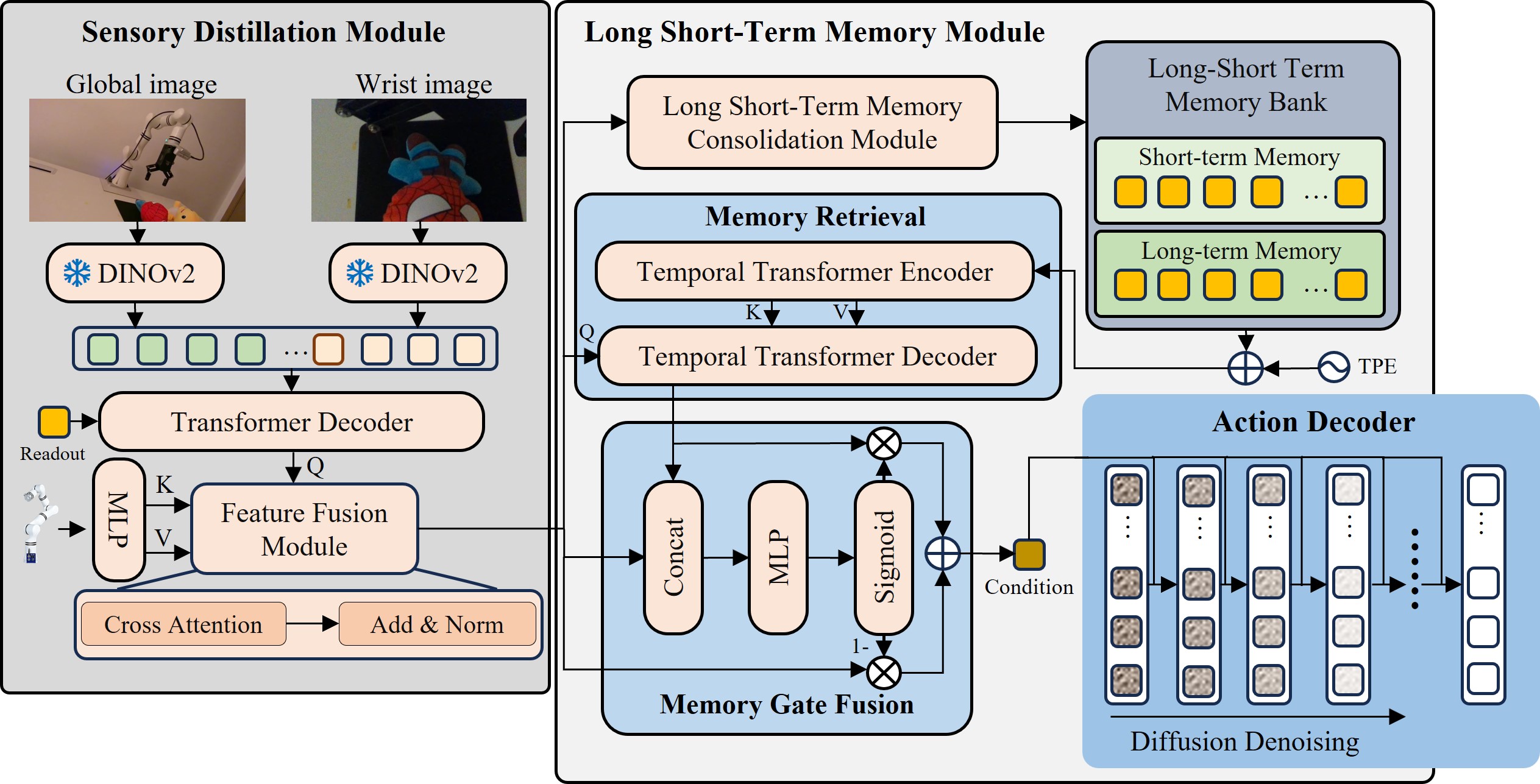
First, the sensory distillation module encodes RGB images and proprioceptive states into high-fidelity sensory memory. Subsequently, the distilled sensory memory queries relevant historical context from the long short-term memory bank. Next, a gating network adaptively fuses the retrieved history with the current sensory memory to produce a condition embedding, which guides the action decoder to iteratively denoise noisy action trajectories into history-aware action trajectories. Finally, the long short-term memory consolidation module updates the memory bank after each forward pass. Please refer to our paper for details.
To evaluate MemoAct, we establish MemoryRTBench with 6 manipulation tasks assessing sequential, spatial, and episodic memory. These three memory dimensions evaluate the ability to execute sub-tasks in the prescribed order, recall the initial scene state after intermediate operations, and repeat a specified task the required number of times, respectively.
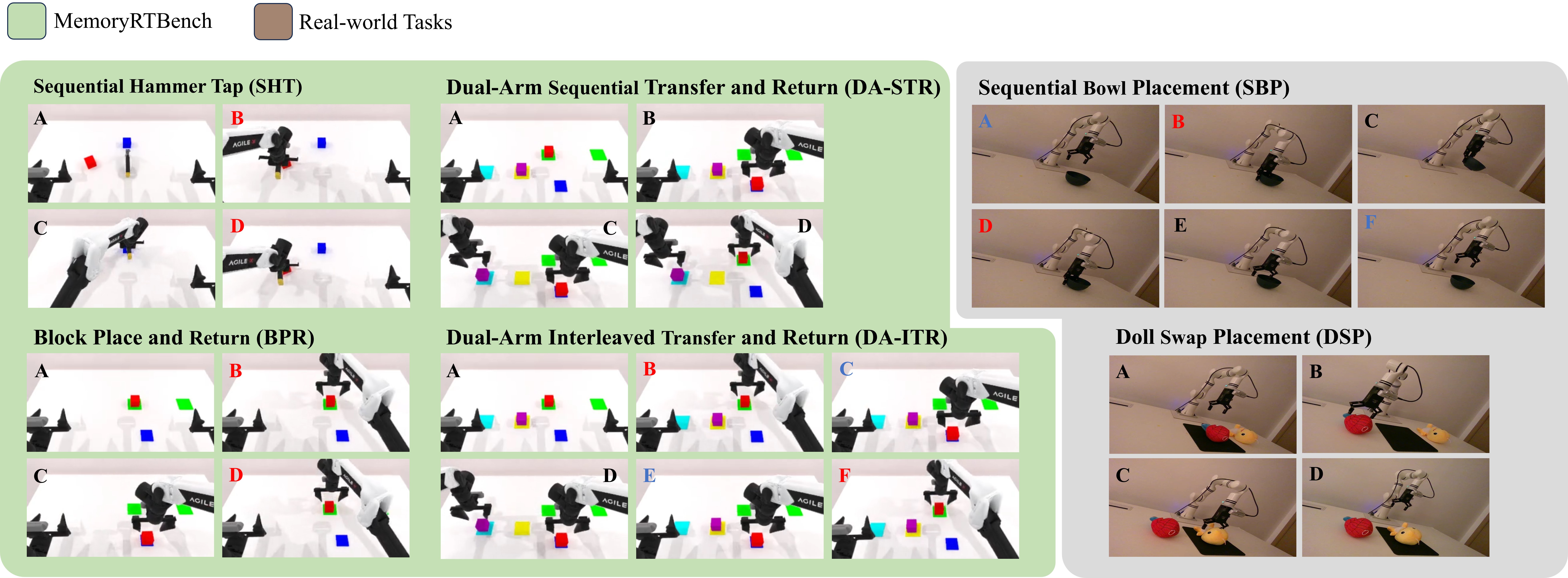
Grasp and Release Bowl
Doll Swap Placement
Sequential Transfer and Return
Block Place and Return
Interleaved Transfer and Return
Sequential Hammer Tap
Lift Bottle Twice
Click Bell Twice and Clock Once
Put Block Back
Click Three Buttons in Order
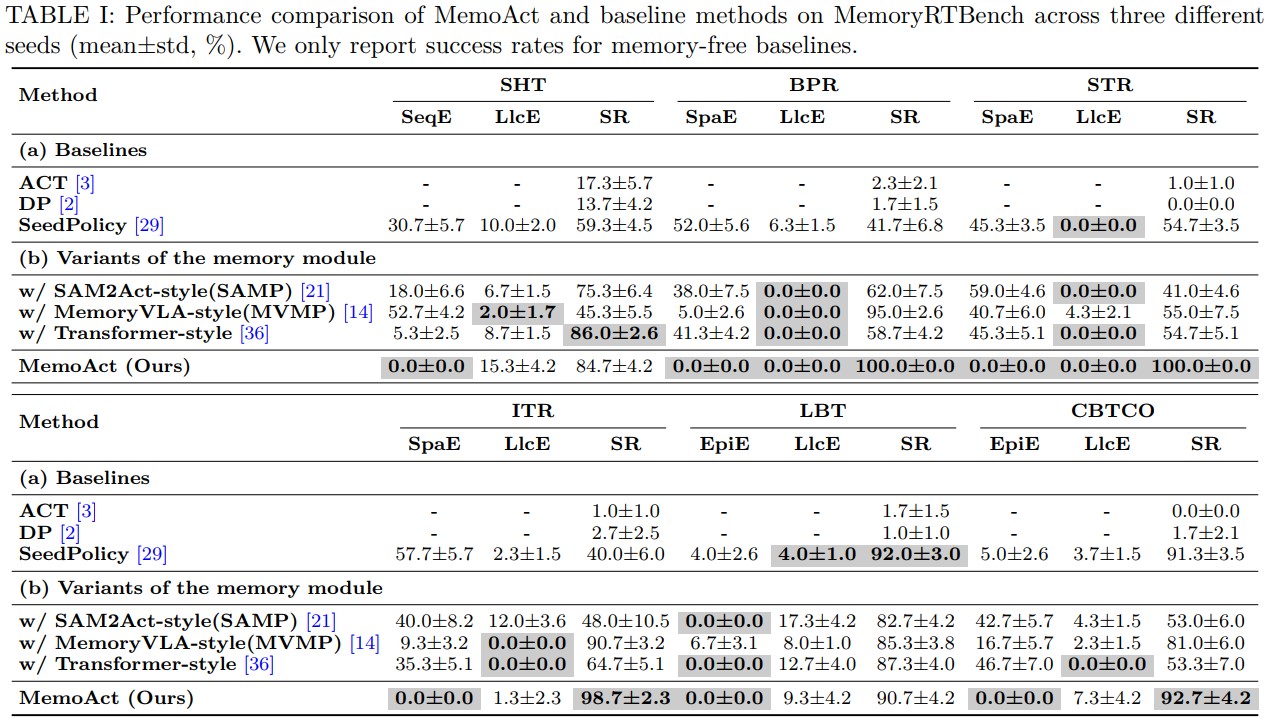
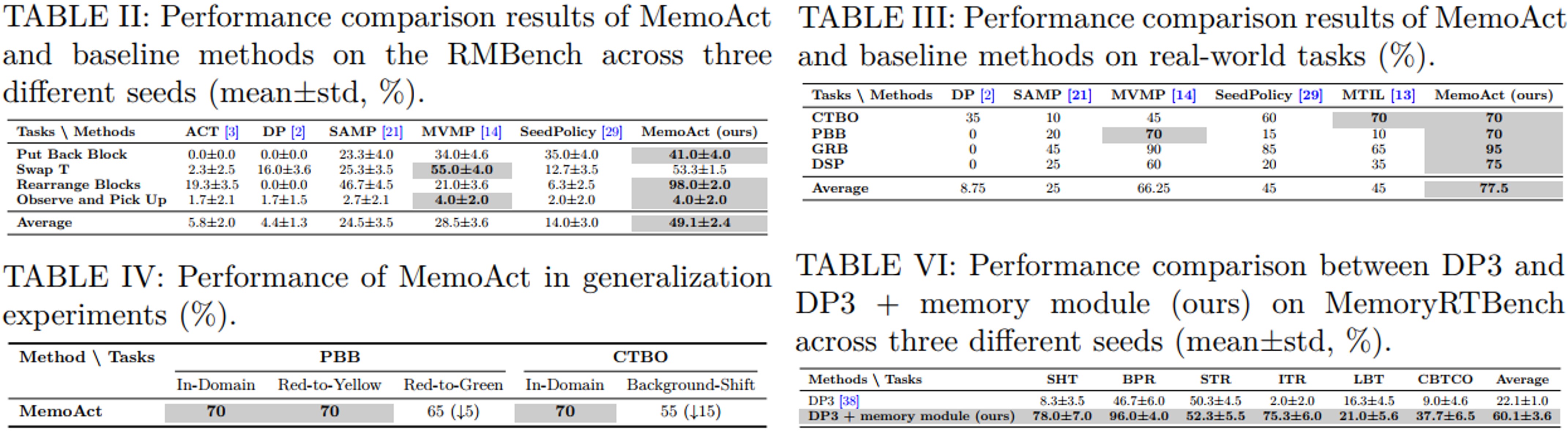
As shown in Tables I, II, and III, MemoAct achieves the best overall performance across simulation and real-world evaluations. It obtains average success rates of 94.5%, 49.1%, and 77.5% on MemoryRTBench, RMBench, and real-world tasks, outperforming the strongest baseline MVMP by 19.1%, 20.6%, and 11.25%, respectively. As shown in Table IV, MemoAct demonstrates certain generalization ability, and its memory module remains effective under distribution shifts. As shown in Table VI, our memory module can be seamlessly integrated into existing policies to improve history-aware decision making.
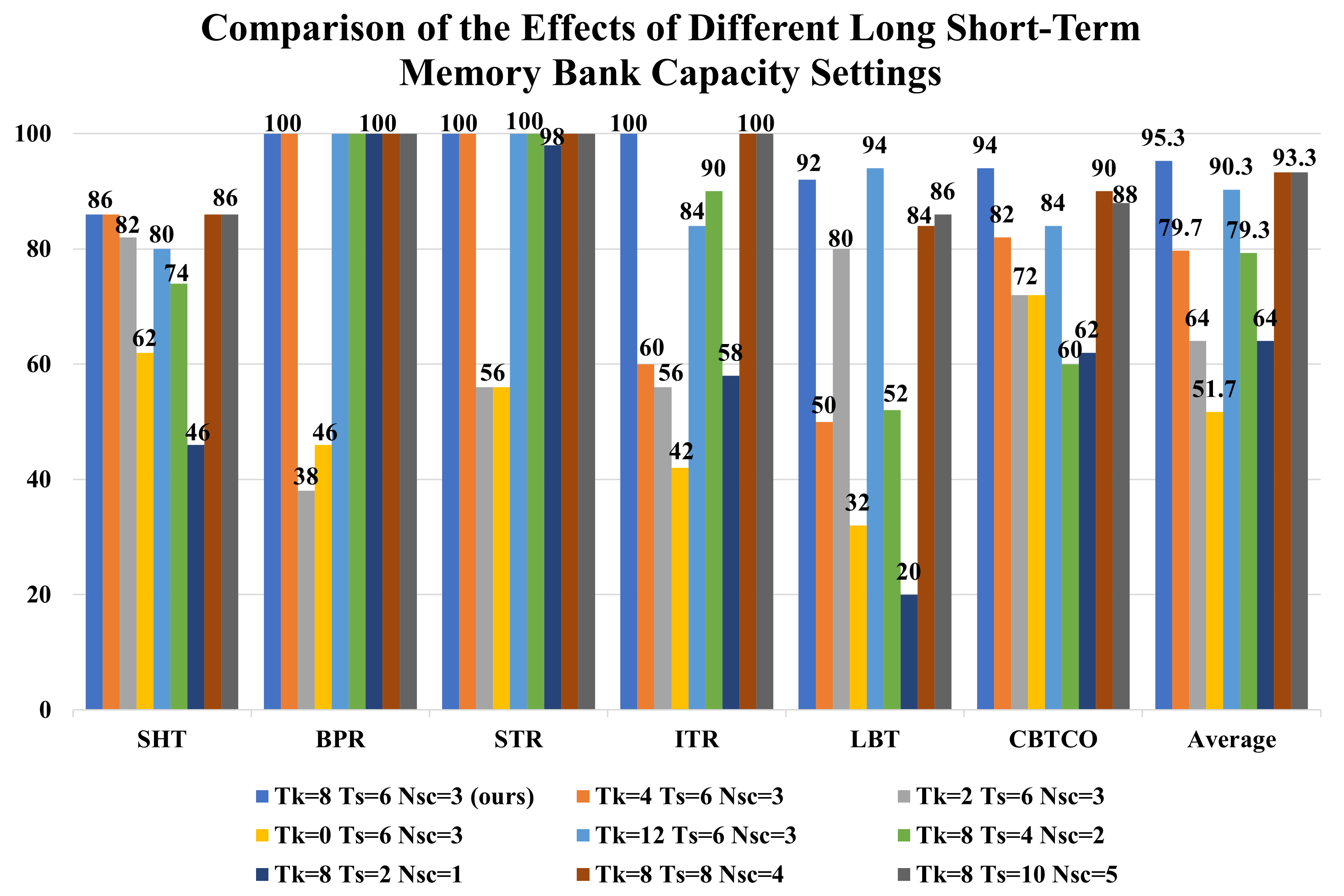
As shown in the figure above, the long-term and short-term memory capacities control long-horizon retention and task-state tracking, respectively.

We conduct an efficiency evaluation using 50 CTBO expert demonstrations with batch size 32. All measurements are conducted on a single NVIDIA RTX 4090 GPU. We measure the parameter count, training time, inference latency, and GPU memory usage for MemoAct and all compared baselines. The results are summarized above.
MemoAct (ours)
MVMP
SAMP
DP
ACT
SeedPolicy
MemoAct (ours)
MVMP
SAMP
DP
ACT
SeedPolicy
MemoAct (ours)
MVMP
SAMP
DP
ACT
SeedPolicy
MemoAct (ours)
MVMP
SAMP
DP
ACT
SeedPolicy
MemoAct (ours)
MVMP
SAMP
DP
ACT
SeedPolicy
MemoAct (ours)
MVMP
SAMP
DP
ACT
SeedPolicy
MemoAct (ours)
MVMP
SAMP
DP
ACT
SeedPolicy
MemoAct (ours)
MVMP
SAMP
DP
ACT
SeedPolicy
MemoAct (ours)
MVMP
SAMP
DP
ACT
SeedPolicy
MemoAct (ours)
MVMP
SAMP
DP
MTIL
SeedPolicy
MemoAct (ours)
MVMP
SAMP
DP
MTIL
SeedPolicy
MemoAct (ours)
MVMP
SAMP
DP
MTIL
SeedPolicy
MemoAct (ours)
MVMP
SAMP
DP
MTIL
SeedPolicy
Unseen Object Color: Red to Yellow
Unseen Object Color: Red to Green
Unseen Background
Unseen Background
Despite these promising results, MemoAct has certain limitations. Since compressing an entire RGB image into a single token via the sensory distillation Module inevitably compromises visual fidelity, MemoAct occasionally makes errors in tasks that are highly sensitive to fine-grained visual information. In future work, we plan to explore adaptive compression mechanisms that better balance memory storage efficiency with visual precision.
LBT
Swap T
SHT
DSP
CTBO Generalization
PBB Generalization